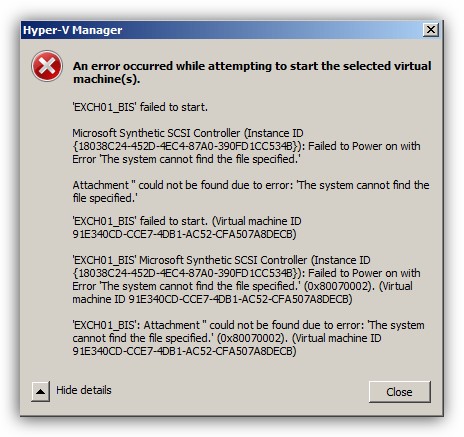
En ocasiones podemos encontrarnos con problemas relacionados con el bloqueo de ficheros al realizar una actualización, eliminación o modificación de una aplicación que requiere acceso y/o uso exclusivo de éstos. Un ejemplo reciente en los que me he visto implicado ha sido en la eliminación de una instalación de Backup Exec donde durante el proceso ha surgido el siguiente error: Continuar leyendo «Process Explorer, una herramienta interesante»
4.486 Visitas del Post