Estimados lectores,
Hoy voy a escribir sobre como forzar un fallo de disco en NetApp, o mejor dicho un pre-fallo que es la operación que realmente hace la cabina. Aunque a priori suene un poco “raro” necesitar un fallo de disco quiero aprovechar la ocasión para exponer un caso real donde me ha sido necesario. El escenario cuenta con un par HA formado por FAS3140 donde están instaladas las míticas DS14mk4, con discos FC de 450Gb, y las más modernas DS4243 con discos SAS de 600Gb. Una de las controladoras cuenta con un agregado formado por los discos FC de 450, aggr0, y con otro agregado, aggr1, formado por los SAS de 600. Estos agregados están configurados ambos en RAID-DP y todos los discos de la controladora están bajo el Pool0 donde encontramos un par de discos de Spare: uno de FC 450Gb y otro SAS de 600Gb.
Puestos en escena, ¿qué ha ocurrido para necesitar forzar el fallo de disco? El aggr0 sufrió un fallo de disco por lo que la controladora empezó la reconstrucción con el Spare FC (lógico, disco de misma tecnología y tamaño). Al poco tiempo “la mala suerte” hizo que nuevamente se produjera un fallo en el mismo agregado antes del reemplazo del disco averiado por lo que la controladora empezó la reconstrucción con el único disco de Spare disponible: el SAS de 600Gb. Este comportamiento es correcto y bajo mi punto de vista adecuado ya que de forma predeterminada se pretende garantizar la integridad de los datos. Ahora bien, ¿qué pasa con el agregado aggr1? No tenemos disco de Spare de 600Gb por lo que la controladora entra en estado crítico informando de ello aunque hayamos reemplazado los discos de 450Gb que habían fallado (recordemos que no podemos reconstruir un agregado con discos de tamaño inferior).
Una vez expuesto el escenario no hace falta ser un crack en Matemática Discreta para ver que tenemos un disco “intruso” en el aggr0 y un par de discos nuevos a la espera de ser usados para este agregado por lo que, ahora sí, necesitamos forzar el fallo del disco de 600Gb para que entre en escena uno de 450Gb y posteriormente nos quede uno de cada tipo tal y como se tenía inicialmente. Vamos con los comandos y la salida de los logs que se generan:
NetApp-David> disk fail 2c.00.11
*** You are about to prefail the following file system disk, ***
*** which will eventually result in it being failed ***
Disk /aggr0/plex0/rg0/2c.00.11
RAID Disk Device HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
--------- -------- --- ----- --- ---- ---- ---- ----- -------------- --------------
data 2c.00.11 2c 0 11 SA:B - SAS 15000 418000/856064000 560879/1148681096
***
Really prefail disk 2c.00.11? yes
disk fail: The following disk was prefailed: 2c.00.11
Disk 2c.00.11 has been prefailed. Its contents will be copied to a replacement disk, and the prefailed disk will be failed out.
NetApp-David> Tue Oct 7 15:26:42 CEST [NetApp-David: raid.rg.diskcopy.start:notice]: /aggr0/plex0/rg0: starting disk copy from 2c.00.11 to 1b.16
Identificado claramente el disco lanzamos el comando para que entre en estado broken como veremos a continuación. Lo que hace la cabina es copiar los datos del disco de 600Gb sobre uno de 450Gb evitando la reconstrucción del agregado, procedimiento mucho más agresivo que requiere recursos para el cálculo de paridad.
NetApp-David> Tue Oct 7 16:15:04 CEST [NetApp-David: raid.rg.diskcopy.done:notice]: /aggr0/plex0/rg0: disk copy from 2c.00.11 to 1b.16 completed in 48:21.99
Tue Oct 7 16:15:04 CEST [NetApp-David: raid.config.filesystem.disk.admin.failed.after.copy:info]: File system Disk 2c.00.11 Shelf 0 Bay 11 [NETAPP X412_HVIPC560A15 NA02] S/N [XXXXXXXX] is being failed after it was successfully copied to a replacement.
Tue Oct 7 16:15:04 CEST [NetApp-David: disk.failmsg:error]: Disk 2c.00.11 (XXXXXXXX): by operator.
Tue Oct 7 16:15:04 CEST [NetApp-David: raid.disk.unload.done:info]: Unload of Disk 2c.00.11 Shelf 0 Bay 11 [NETAPP X412_HVIPC560A15 NA02] S/N [XXXXXXXX] has completed successfully
Tue Oct 7 16:15:20 CEST [NetApp-David: asup.smtp.sent:notice]: Cluster Notification mail sent: Cluster Notification from NetApp-David (FILESYSTEM DISK ADMIN FAILED) INFO
Tue Oct 7 16:15:54 CEST [NetApp-David: asup.post.sent:notice]: Cluster Notification message posted to NetApp: Cluster Notification from NetApp-David (FILESYSTEM DISK ADMIN FAILED) INFO
Como podemos ver pasados unos minutos la controladora informa que ha terminado de copiar los datos y que el disco «intruso» se ha liberado informando de ello mediante mensajes AutoSupport.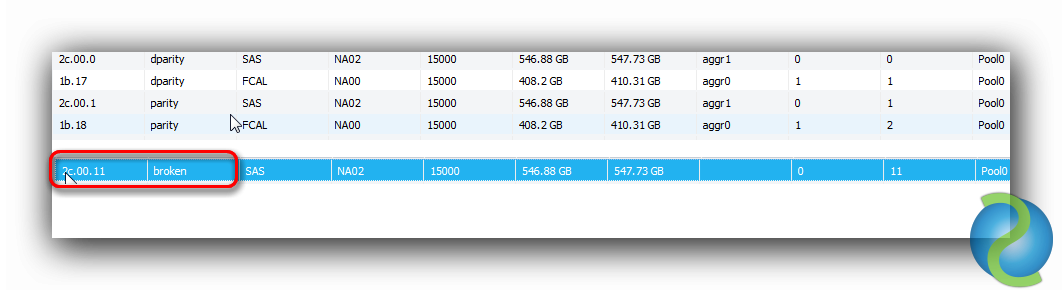
Desde OnCommand System Manager podemos ver el estado del disco tras la operación (disco roto o broken). Para configurar este disco como Spare lanzaremos el comando siguiente:
NetApp-David> priv set advanced
Warning: These advanced commands are potentially dangerous; use
them only when directed to do so by NetApp
personnel.
NetApp-David*> disk unfail -s 2c.00.11
disk unfail: unfailing disk 2c.00.11...
NetApp-David*> Tue Oct 7 16:31:07 CEST [NetApp-David: raid.disk.unfail.done:info]: Disk 2c.00.11 Shelf 0 Bay 11 [NETAPP X412_HVIPC560A15 NA02] S/N [XXXXXXXX] unfailed, and is now a spare
Tue Oct 7 16:32:00 CEST [NetApp-David: monitor.globalStatus.ok:info]: The system's global status is normal.
Es necesario acceder al modo avanzado para permitir deshacer el fallo del disco y la correspondiente «conversión» a Spare. Con este procedimiento hemos devuelto la normalidad al sistema tal y como nos informa el Global Status.
![]()
This Post by David Solé Pérez is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License





Un comentario en “Como forzar un fallo de disco en NetApp”