En esta nueva entrada vamos a ver cómo identificar un hot disk en NetApp y los efectos de impacto sobre el rendimiento de nuestro sistema de almacenamiento. Cuando se inicializa una controladora NetApp con la correspondiente asignación de discos y creación de nuevo filesystem, de agregado root, todos los discos que conforman los RGs están disponibles para recibir bloques de datos (recordemos que NetApp distribuye equitativamente los datos dentro de un agregado para poder usar todos los cabezales de disco optimizando así el rendimiento de acceso). Esto quiere decir que los bloques de datos de los volúmenes se van a «seccionar» ubicándose «por igual» en todos los discos:
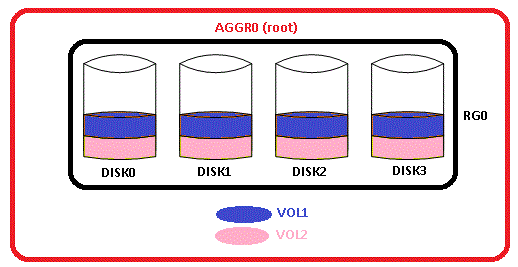
De forma esquemática podemos ver esta distribución de los datos. El resultado, en términos de rendimiento, es un porcentaje de utilización muy similar en cada uno de los discos de manera que se equilibra la carga de trabajo sobre cada uno de ellos. La realización de dicho resultado se obtiene monitorizando los discos con la combinación de statit y sysstat en el procedimiento siguiente:
1) Entrar en modo diag: priv set diag
2) Lanzar el comando statit -b
3) Lanzar el comando sysstat -x 1
4) Esperar un tiempo para el muestreo (30 segundos por ejemplo). Detener la salida con Ctrl. + C
5) Lanzar el comando statit -e
6) Se muestra la salida de las estadísticas de rendimiento
Los datos obtenidos se asemejan al siguiente ejemplo:
disk ut% xfers ureads--chain-usecs writes--chain-usecs cpreads-chain-usecs greads--chain-usecs gwrites /aggr0/plex0/rg0: 0c.00.1 2 3.35 0.51 1.06 27529 2.21 7.10 594 0.62 4.56 1691 0.00 .... . 0.00 .... . 0c.00.3 3 3.51 0.51 1.06 33912 2.37 6.76 613 0.62 3.77 2109 0.00 .... . 0.00 .... . 0c.00.5 61 69.25 67.97 2.29 14098 0.86 13.57 1196 0.42 7.12 2930 0.00 .... . 0.00 .... . 0d.01.13 52 68.21 67.23 2.23 11048 0.62 19.03 1214 0.35 8.82 1505 0.00 .... . 0.00 .... . 0d.01.9 52 65.46 64.35 2.22 11568 0.70 16.80 1334 0.40 5.96 2725 0.00 .... . 0.00 .... . 0d.01.7 56 67.33 66.16 2.20 12739 0.72 16.51 1402 0.45 5.96 2323 0.00 .... . 0.00 .... . 0d.01.15 58 69.62 68.40 2.15 13505 0.70 16.82 2203 0.51 6.22 2191 0.00 .... . 0.00 .... . 0c.00.7 59 66.26 65.20 2.14 15754 0.61 20.00 1120 0.45 7.14 1690 0.00 .... . 0.00 .... . 0c.00.9 60 66.99 65.97 2.21 15146 0.64 18.68 1112 0.38 4.88 3556 0.00 .... . 0.00 .... . 0c.00.11 61 67.86 66.80 2.14 15463 0.70 16.89 1560 0.35 5.18 4307 0.00 .... . 0.00 .... . 0d.01.11 55 68.10 67.01 2.17 12225 0.64 18.68 1451 0.45 5.61 3096 0.00 .... . 0.00 .... . 0d.01.5 54 69.81 68.64 2.21 12075 0.72 16.49 1581 0.45 4.43 4435 0.00 .... . 0.00 .... .
En general siempre observaremos un porcentaje de uso bajo o muy bajo en los discos de parity y dparity. En el resto de discos de /aggr0/plex0/rg0, los data, deberíamos tener un uso similar. En el caso de observar un % desmesurado respecto el resto de discos del conjunto podríamos estar ante un caso de hot disk por lo que se requeriría el uso de reallocate para reubicar los bloques de datos de forma homogénea. Este caso se puede dar al ampliar un agregado con nuevos discos que resultarían en un mayor espacio libre contiguo que podría ubicar más bloques de datos de los deseados no uniformemente.
En el ejemplo anterior hemos tomado una muestra de 30 segundos donde observamos un uso medio de todos los discos. Podemos ejecutar este procedimiento tomando varias muestras con diferentes tiempos y ventanas horarias para poder sacar conclusiones (en este caso no hay hot disk).
Estemos o no en un caso de estas características podemos lanzar el comando reallocate measure /vol/nombre_volumen, cuyo resultado será un entero de valor 3: moderadamente optimizado hasta 10:muy desoptimizado siendo 4:predeterminado, para medir si es necesario reubicar los bloques de datos optimizando el rendimiento del sistema de almacenamiento. Podemos consultar la guía Reallocate Best Practices.
![]()
This Post by David Solé Pérez is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License






