El sistema de archivos que usan las controladoras Netapp, Write Anywhere File Layout, está basado en Inodes de la misma forma que los sistemas UNIX/Linux. De hecho la Shell de Ontap se asemeja bastante a UNIX por la naturaleza de sus comandos.
La descripción que NetApp hace de un Inode la podemos consultar aquí (requiere una cuenta de registro).
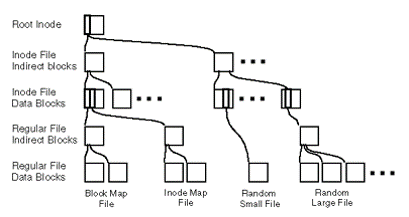
El tamaño de bloque de WAFL es de 4KB y cada Inode está formado por 16 punteros así que para ficheros de menos de 64KB, cada puntero apunta a un bloque de datos. En el caso de ficheros muy pequeños (menos de 64KB) los datos se mantienen en el propio Inode. Para el caso de ficheros grandes o muy grandes se usan punteros a bloques indirectos o dobles punteros.
Los meta-datos de WAFL se almacenan en archivos siendo éstos los siguientes:
1) Inode File: almacena los Inodes del sistema de archivos.
2) Block Map File: almacena los bloques libres.
3) Inode Map File: identifica los Inodes libres.

El Inode raíz debe permanecer en una ubicación fija. Los demás bloques se pueden escribir en cualquier ubicación (de ahí el nombre Write Anywhere).
De entre muchas funcionalidades presentes en un sistema WAFL sin lugar a dudas la más famosa son los Snapshots. La secuencia siguiente muestra un ejemplo de su funcionamiento:
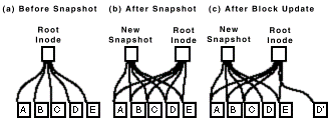
En realidad cuando se crea un Snapshot se copia el Inode raíz manteniendo los punteros a los bloques originales. Cuando un bloque se modifica el Inode raíz apunta a un nuevo bloque indirecto:

Analizando este comportamiento se concluye lo siguiente: cuando se genera un nuevo Snapshot el espacio que éste ocupa es prácticamente de unos pocos KBs correspondientes al clonado del Root Inode. Como lo inmediatamente posterior a un primer Snapshot es el Active Filesystem, la información «viva», los bloques se van modificando produciendo un aumento proporcional del espacio consumido por el Snapshot (a mayor número de cambios más espacio consume el Snapshot). Por este motivo los Snapshots de volúmenes con pocos cambios, como por ejemplo un repositorio de backups, consumen mucho menos espacio que aquellos que sí los tienen, una base de datos Oracle por ejemplo. Además de esto último un factor a tener en cuenta es el número de inodes/bloques implicados ya que, lógicamente, no es lo mismo hacer un cambio en un VMDK de 300GBs que un fichero de Excel de 3MBs.
Para finalizar esta pequeña introducción a WAFL comentar que este filesystem tiene unos Snapshots especiales denominados consistency point que se generan cada pocos segundos para evitar realizar test de integridad en el caso de desconexión del sistema de almacenamiento (fallo eléctrico por ejemplo). En cada CP se escriben los datos a disco y, entre la creación de uno y otro, la información solamente se escribe en RAM la cual está protegida por la NVRAM (los bloques de RAM pasan a la NVRAM a modo de Backup). De forma esquemática se podría definir este funcionamiento como sigue:
1) Partimos de cero escribiendo datos en el sistema de almacenamiento que se ubican en la RAM principal.
2) Los datos escritos en RAM se ubican en la NVRAM a modo de Backup para casos de fallo.
3) El filesystem crea un CP por lo que los datos se consolidan a disco.
4) Seguimos escribiendo datos en RAM y éstos pasan a la NVRAM.
5) Nuevamente se genera un CP para consolidar los datos.
La secuencia anterior es «infinitamente recursiva» mientras no se produzca un paro controlado o bien se de un caso de fallo. Si el sistema sufre un paro inesperado entonces la NVRAM se mantiene alimentada por la NVRAM Battery durante un máximo de 72 horas, tiempo más que suficiente para arrancar nuevamente los discos y poder así consolidar los cambios.
![]()
This Post by David Solé Pérez is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License





